a/a+:
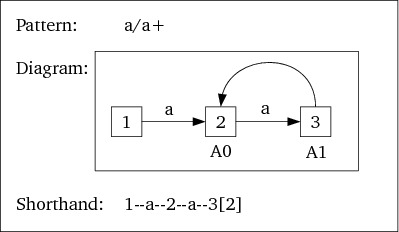
Here, State 2 is the Final state
a*/aaa: All a symbols until
the F-state (state 5) has been reached are counted:
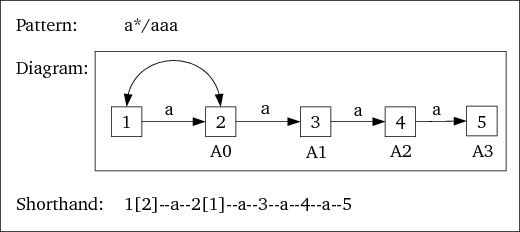
The resulting DFA becomes:
| Input Ch | |||
| StateSet | a | F | |
| 12 | 123 | ||
| 123 | 1234 | ||
| 1234 | 12345 | ||
| 12345 | 12345 | 0 | |
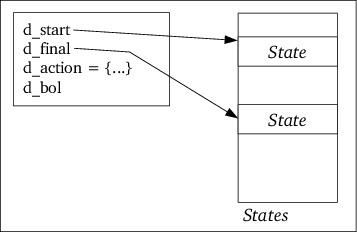
States and Rules. The parser is described here.
After some preliminary definitions flexc++ defines its Parser
object. The parser's main tasks are these:
parse: the input is analyzed, resulting in the definitions of
rules. Each regular expression consists of a series of states, summarized
by Patterns and an action block. Action blocks may be empty, and may
be identical for subsequent regular expressions. A Pattern plus action
block (plus maybe a begin-of-line indicator) becomes a rule which
is added to the Rules object. The first regular expression in the input
file becomes rule 0.
addLopStartConditions: once the input has been parsed, and LOP-rules
were recognized the LOP start conditions need a catch-all rule. The catch-all
rule looks like this:
.|\n lop3_();
and is added by the scanner to the input once all input files have been
processed. This rule is then used in the LOP-tail matching procedure,
explained in section 6.10.
After parsing the Rules object's handleLopRules adds a catch-all rule
to the LOP rule processing code. This member also updates the LOP-rules
action blocks, calling lop1_, lop2_, lop3_ and lop4_. Again:
refer to section 6.10 for details.
Rather than using the characters groups of characters are combined, forming
clusters or ranges. This way the DFAs do not need column entries representing
the individual input characters, but only need columns representing the
categories, usually resulting in strongly reduced column dimensions. The
ranges are determined by the Ranges object. These ranges can only be
determined once the regular expressions have been analyzed, which is why the
Ranges object is defined and performs its actions after the parser has
completed its work.
Once the ranges and the states of the regular expressions have been
determined, the DFAs can be constructed. A DFA is constructed for each start
condition (i.e. start condition) by the DFAs object.
Finally, a Generator generates the output files. The Generator reads
the skeleton files, copying them to their destinations which inserting
information (like the range definitions and DFA tables) which was created
before.
BOL: Begin-of-line.
LOP: the lookahead operator (/).
RE: A regular expression.
F: A final state.
x[y]: at state x an empty transition to state y is allowed.
See figure 2.
F state of a LOP pattern is reached and there is no
continuation at that point then the pattern until the A0 state is considered
matched and is returned.
a/a+:
Here, State 2 is the Final state
a*/aaa: All a symbols until
the F-state (state 5) has been reached are counted:
The resulting DFA becomes:
| Input Ch | |||
| StateSet | a | F | |
| 12 | 123 | ||
| 123 | 1234 | ||
| 1234 | 12345 | ||
| 12345 | 12345 | 0 | |
Parser parser(rules, states);
parser.parse();
The constructor performs no other tasks than initializing the Parser object.
Rules and states are still empty at this point.
The parse function was generated by bisonc++(1). It's better
understood from the grammar description parser/grammar: The grammar's
start rule is
input:
opt_directives
section_delimiter
rules
;
parser/inc/rules: The directives are not covered yet in this section. A
rule is defined as:
rules:
rules _rule
|
// empty
;
As a notational convention, all non-terminals not used outside of the file in which they are defined start with an underscore. Furthermore, wherever possible rules are defined before they are used. This cannot always be accomplished, e.g., when defining indirectly recursive rules.
A _rule is a rule definition followed by a newline:
_rule:
_rule_def '\n' reset
;
The reset non-terminal merely calls Parser::reset, preparing the
parser for the next rule, resetting various data members to their original,
begin-of-line states. See parser/reset.cc for details.
A _rule_definition may be empty, but usually it consists of a rule
optionally valid for a set of start conditions (optMs_rule, or it is a
rule or series of rules embedded in a start condition compound (msComound):
_rule_def:
// only an empty line is OK
|
// recovery from errors is OK: continue at the next line
error
|
optMs_rule
|
msCompound
;
The msCompund isn't interesting by itself, as it repeats
optMs_rule, but without the start condition specifications for the individual
rules.
An optMs_rule is a rule (_optMs_rule), optionally followed by an
action:
optMs_rule:
// just regular expressions, without an action block
_optMs_rule
|
// the scanner returns a block if it encounters a non-blank character
// on a line after ws, unless the character is a '|'
_optMs_rule action
{
assignBlock();
}
;
An _optMS_rule defines one or more rules, sharing the same action
block:
_optMs_rule: // after ORNL continue parsing
_optMs_rule ORNL '\n' reset _optMs_rule // at a new line
{
orAction();
}
|
_optMs_regex
{
addRule($1, true); // true: reset the miniscanner spec to INITIAL
}
;
And an _optMS_regex, finally, is a regular expression or EOF-pattern,
optionally prefixed by a start condition specification:
_optMs_regex:
ms_spec regexOrEOF
{
$$ = $2;
}
|
regexOrEOF
;
A regexOrEOF defines exactly that:
regexOrEOF:
_regex
|
EOF_PATTERN
{
$$ = eofPattern();
}
;
Actions are defined here; the Rules class is described
here; Regular expressions (i.e., regex) are described
here.
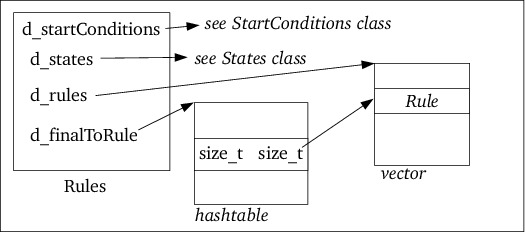
StartConditions object. Each start
condition's name and start condition information is stored in d_sc, an
FBB::LinearMap, the first one being the INITIAL start condition.
Start condition information consists of the start condition's type and a
vector of size_t values, being the rule indices of the rules that were
defined for this start condition.
Additional members are d_endUserSC, storing d_sc's size after all user
defined start conditions have been inserted into d_sc. As all user-defined
start conditions must have been declared in the declaration section, this
value is known before start conditions are created by flexc++ when encountering
LOP-rules.
Furthermore, a member d_active hold pointers to all currently active start
conditions. E.g., when specifying <INITIAL,str> then the rules defined for
this tag are active are added to the set if rules defined for
StartConditions_::INITIAL and StartConditions_::str.
When LOP-rules having variable sized tails are used, flexc++ defines a catch-all
rule which is mathed while lex_ is trying to match the LOP-rule's tail,
but as yet failed to do so. When it is defined this catch-all rule does not
belong to a particular start condition. This is relized through the member
StartConditions::acceptRule, expecting a bool argument. By default
recognized rules are added to the current set of active start conditions, but
the catch-all rule should not be added to any active set. Instead it is
added to the DFAs calling lop3_. Once the input files have been
processed, Rules::handleLopRules is called, and this member adds the final
(catch-all) rule to d_rules, without adding it to any of the available
start conditions.
{ until the
final matching }, acknowledging comment, strings and character constants.
The scanner merely recognizes the beginning of an action (block), returning
Parser::BLOCK from its handleCharAfterBlanks member. Then,
Parser::block calls Scanner::lex() until it observes the end of the
action statement or block.
The parser stores the block's content in its d_block member for later
processing by Rules::add.
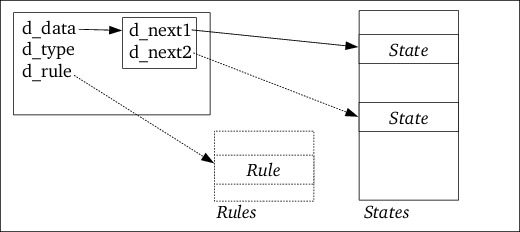
State describe one single state of a RE
pattern. A State contains/offers:
d_type: the type represented by the State (EMPTY, FINAL, CHARSET,
BOL), the internally used UNDETERMINED_ and EOF_ types, or
(initially) the ascii-value of a single character. Once the character
ranges have been determined (see section 6.11), which happens
in ./main.cc `ranges.determineSubsets()' the type contains the
(0-based) range index, and states reprenting character sets also
contain the set of character range-indices that apply to those sets
(this is implemented in ./main.cc's line ranges.finalizeStates()').
No other type may occur (if another type is encountered flexc++ contains
an internal logic error and the program terminates in a fatal
exception).
d_rule: an index into the Rules object to the
rule object defining the pattern;
StateData. The class StateData contains
two indices: the State indices of the states following the current
State (or 0 if this state represents a final state). The second
index (d_next2) may be 0, indicating that there is no second
continuation state. It is unequal 0 when the
alternate operator ('|') is used in a RE.
Starting from a pattern's initial state all its subsequent states can
therefore be reached by visiting the indices stored in
StateData.
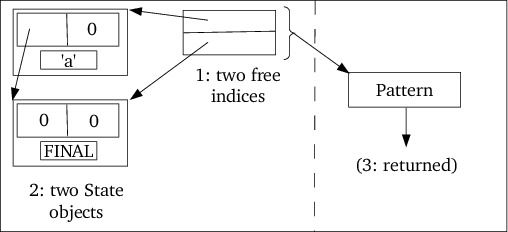
States class object stores all the states defined by all Pattern
objects (d_states). When a new pattern is requested the member next or
next2 can be invoked to obtain the next or next two free states. Since
concatenating pattern produces free states (cf. the description of the
pattern concatenation) a vector of free state indices is
maintained by the States class as well (d_free).
The member next2 returns a pair of free state indices, the second state
index refers to a State that has been initialized to the end-of-pattern
state: its state type is State::FINAL and its two successor (next)
fields are set to 0, indicating that there is no continuation from this state.
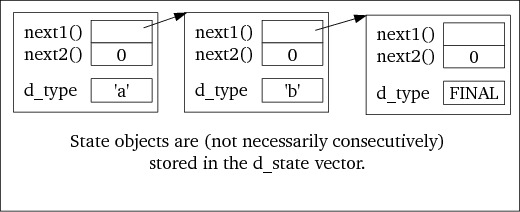
Patterns consisting of multiple states (like the pattern ab, consisting of
the state holding a and the state holding b) are stored in a
linked-list like structure, implemented using the States's d_state
vector. Its representation is as follows (cf. figure 5:
next1() member of the state containing the a pattern
returns the index of the state containing the b pattern.
next1() member of the state containing the b pattern
returns the index of the final state
next1 and next2 members return 0
|-operator (pattern |
pattern) all next2 members return 0. The implementation of the
|-operator is described here.
Pattern objects and associated
action blocks) are accessible from the Rules object. The Rules object
contains a reference to the states (see here), and a vector
d_rules containing the information about each of the rules, and a hash
table linking a final state index back to its rule number (see figure
6)
When the parser has recognized a rule it calls Rules::add. A Rule
object is added to d_rules, storing begin and end state indices, a flag
indicating whether or not this rule's RE started at BOL. A rule also contains
the code of any action block that's associated with it (empty if there are no
actions), see also section 6.4.
Rules::add also stores the association between the rule's final state and
rule index in its unordered_map d_finalToRule. Furthermore, it calls
d_startConditions.add(ruleIdx) to store the rule index at the currently
active start conditions. See section 6.3 for the class
StartConditions.
States of rules using the LOP need access to the rule to which they
belong. For those rules Rules::setRuleIndices is called to assign the
State's d_rule field.
The Rule object themselves have an organization shown in figure
7.
Rules starting with ^ can only be matched at begin-of-line
(BOL). The data member d_bol of such rules is set to true.
Rules that are matched in some DFA state are viable: such rules can be matched. See section 6.15 for a description of the algorithm that is used for finding (non)viable rules.
Pattern objects (cf. section
6.9). Basically, a Pattern contains the begin- and end-states
of a RE.
Various types of REs are processed by various class-type factory functions,
constructing Pattern objects. The file parser/inc/regexoreof uses
these factory functions when their type of RE has been recognized.
[[:digit:]]) are handled by
class CharClass (cf. section 6.8.1);
{1, 3}) are handled by class
Interval (cf. section 6.8.2);
Pattern::rawText factory functions. Strings are received
as-is, and their surrounding double quotes are removed before
rawText is called. The contents of rawstrings is directly received
from the scanner. Escaped characters in strings are unescaped before
they are processed by Pattern::rawText.
*, +, ?) are directly handled by Pattern factory
functions, receiving the regular expression and the multiplier, and
returning a new Pattern incorporating the multiplication.
Pattern::concatenate factory
function;
|) are handled by the
Pattern::alternatives factory function;
lookahead member, calling
Pattern constructors defining lookahead patterns.
<<EOF>> end-of-file pattern is handled by the
Pattern::eof factory function.
CharClass
objects. A CharClass object initially stores all characters of its set in
a string, while remembering the offsets where series of ordinary
characters or predefined character ranges start in a vector of pair<size_t,
CharType> objects. Their first members are indices in the object's
string data member where one or more characters of type CharType
start.
CharType is an enum having values CHAR, indicating a plain character;
PREDEF, indicating a character in a predefined range; and END, which
is used for offset d_str.length().
Once all elements of a character class have thus been collected, the member
str may be called to create the final character set.
The member set creates the final set of characters. It calls
handleMinusAndEscapes to find (tag) all minus characters in d_str, and
to process any escape sequence that may have been used in the set. Since flexc++
2.00.00 escape sequences inside character sets are supported. Thus, to
represent a literal minus character \- can be used. The member
handleMinusAndEscapes passes each of the sub-strings in d_str
(starting at the elements in d_type) to inspect. Inspect only
inspects CHAR ranges. It processes all escape-sequences in the CHAR
range, and stores the locations of unescaped minuses in d_tag, thus
tagging the locations of potential character-range operators. The tags of minus
characters that are used as the first or last character in d_str are
removed, as initial or final minus characters do not define a range.
Next, the tagged minus characters are inspected. These minuses must define valid ranges, which means:
a-c-g is an invalid range: two ranges may not
share a common boundary);
char collating
sequence. Here, flexc++ uses the standard (signed) 8-bit char
type.
All characters found in d_str to the left of a range are then inserted
into a set<char>. Next the characters of the character range are
inserted. Once all character ranges have thus been processed, any trailing
characters are added to d_str.
The member str() receives the set, stores its elements in d_str, and
returns d_str. Although currently not used by flexc++'s implementation,
str also sets the CharClass object's d_state to FINAL: once a
CharClass's state is FINAL its d_str is not modified anymore, and
str will return d_str without calling set.
Interval is a simple support class defining the lower and upper
bounds of an interval as size_t values. It uses std::string conversion
functions to convert values stored in text format in std::string arguments
to size_t values.
The class defines two size_t values (d_lower and d_upper) and
several factory members as well as members to access d_lower and
d_upper's values.
parser/rules/pattern: Patterns define the regular expressions that can be
matched. All patterns start at pattern_ws and consist of:
pattern_ws:
pattern opt_ws mode_block
;
Following the recognition of a pattern, the scanner is reset to its
block mode, allowing it to recognize a C++ action block. Blocks are
defined here.
The following patterns are defined (more extensive descriptions follow):
EOF_PATTERN - recognized by the lexer, matching <<EOF>>.
STRING - recognized by the lexer, matching a literal string.
SECTION_DELIMITER - recognized by the lexer. The %% sequence in
fact ends the rule section
character_class: a self-defined or predefined character class like
[a-c] or [[alpha]].
plain_characters: any plain character, like a in ape.
ESCAPE_SEQUENCE: characters defined by escape sequences, like
\x2a. To the parser they are plain characters.
'.': the any-character-but-newline matching pattern.
pattern pattern: two patterns immediately following each other. These
two patterns have the precedence of CHARACTER, and are combined
left-associatively.
pattern '|' pattern Two alternative continuations.
pattern multiplier: multipliers are *, + and ?.
'(' incParen pattern ')' decParen a pattern nested in parentheses
pattern '{' start_interval_m interval '}' regex_block_m a repetition
using curly braces (an interval repetition)
pattern '/' pattern a lookahead pattern ($ is handled by the scanner)
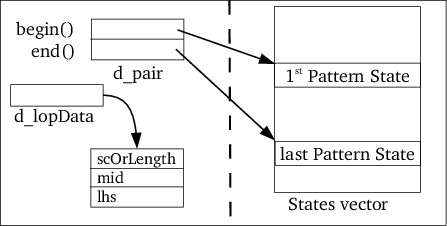
Pattern objects contain (and offer, through the members begin and
end) index values in the States::d_states of State objects. The
value returned by Pattern::begin() is the index of the first State
defining the pattern, the value returned by Pattern::end() is the index
of the last (so: State::FINAL) State of the pattern (cf. figure
8).
Pattern objects also have a d_lopData data member, which is a pointer
to an internally used LopData struct. This data member is only used with
LOP-patterns, and is covered in section 6.10.2.
parser/rules/pattern: the following descriptions of the working of some
basic patterns illustrate how the vector of State objects in States is
filled. Based on this description other pattern's implementations should be
evident.
A basic pattern is the plain character (parser/inc/regexoreof:
_single_char, processed by the Pattern::rawText factory function). The
plain character pattern is processed as follows:
State vector locations are
requested (see the next2 description in the
States clas).
State at the first state index is then set to a state
containing the plain character, linking to the next free state which has been
initialized to the FINAL state by States::next2.
Pattern, storing the begin and end State indices, is
returned (cf. figure 9).
Concatenation of two patterns always produces a free State that can be
returned by, e.g., State::nex2. The states, defining a pattern,
therefore, do not have to be consecutively stored in the States's vector
of State objects (see figure 10).
SemVal objects.
SemVal objects are downcast to,
resp. a lhs PatternVal and a rhs PatternVal.
lhs pattern may be an accepting
state. I.e., once the full pattern has been recognized only the lhs is
actually matched. E.g., after recognizing a/b a is returned as
matched, as a is the accepting pattern. When concatenating the lhs's end
state disappears and is replaced by the rhs's begin state. Therefore:
lhs.end() state is assigned the value of the rhs.begin()
state
rhs.begin() state is marked as free
Pattern is returned, having its
begin index set to lhs.begin() and its end idex set to
rhs.end().
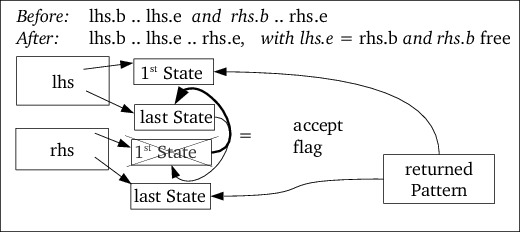
/) is handled has
completely changed at flexc++'s upgrade from version 1 to version 2. The
LOP-handling algorithm used in flexc++ versions before 2 worked correctly in
most situations, but we were unable to prove its correctness, and over time
bugs in the algorithm were uncovered which often were very hard to squash.
On the other hand, the algorithm implemented since flexc++ version 2 is surprisingly simple and can be proven to work.
The philosophy underlying the current LOP algorithm is simply that, in order
to match {head}/{tail}, where {head} and {tail} are regular
expressions, the scanner must at least be able to match {head}{tail}: the
concatenation of {head} and {tail}.
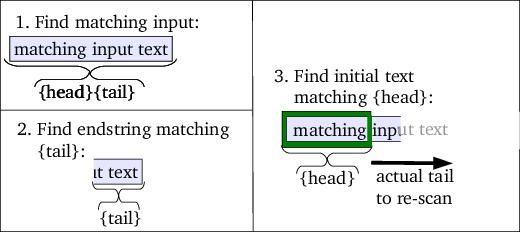
Lookahead tail patterns, however, must match input strings which should be as
short as possible. To find this shortest tail pattern the scanner tries to
match the last character of the text that matched {head}/{tail} with the
{tail} pattern. If this succeeds, then the shortest tail was found. If the
last character didn't already match {tail} then the last two characters
are matched against {tail}. This process (i.e., increasing the length of
the final substring of the input matching {head}{tail}) is continued until
{tail} is eventually matched. This must succeed since, after all, the full
input matched {head}{tail}. Thus a short tail was found matching
{tail}.
After matching the tail pattern, the matching final substring is removed from
the original input string, and the initial substring is passed to the
{head} pattern, thus finding the longest match, given that the
remaining characters of the matched text still match {tail}. Figure
11 illustrates the algorithm.
Some minor optimizations handle potentially zero length tails and handle fixed
tail lengths. With potentially zero length tail lengths (e.g.,
{head}/{tail}*) the scanner ignores the tail and replaces
{head}/{tail}*) by {head}). With fixed tail lengths the length of the
tail (|tail| is known, and the final |tail| characters of the matched
input text can immediately be pushed back on to the input stream, returning
the remaining text as the text matching {head}.
The following subsections describe how flexc++ recognizes and handles LOP-patterns. The next section (6.18) describes the run-time handling of LOP-patterns.
parser/inc/regexoreof. LOP-patterns are recognized using
_regex '/' _regex
{
$$ = lookahead($1, $3);
}
Here _regex represents a regular expression pattern, stored in
Pattern objects.
The parser's member lookahead verifies that a regular expression contains
but one LOP, and that the LOP is not used in a parenthesized regular
expression. If the rhs pattern can be empty the rhs is ignored and the lhs
pattern is returned. If the rhs pattern has a fixed non-zero length the
Pattern constructor
Pattern(States &states, size_t tailLength,
Pattern const &lhs, Pattern const &rhs);
is called to define a pattern having a fixed length tail. Otherwise a
variable (standard) LOP-expression was encountered.
Standard LOP expressions are handled according to the algorithm
illustrated in figure 11. This is implemented using two
separate startconditions (see the next section (6.10.1.1)).
Until the tail pattern is actually matched, its length is gradually
increased. This is handled by a catch-all rule (using the pattern .|\n)
which can be added to the scanner's input, and which is used as fall-back rule
in tail-matching start conditions (see section 6.10.1.1).
{head}/{tail} action-block
results in two additional start conditions x and x+1, which are
defined only for handling this LOP-pattern. Flexc++ generates code in which the
above regular expression is transformed into rules that would have looked like
this in a flexc++ specification file:
{head}{tail} lop1_(x);
<x>{
{tail} lop2_();
.|\n lop3_();
}
<x+1>{head} {
lop4_();
action-block
}
Once {head}{tail} is matched (see also figure 11), an
internally defined member lop1_(x) is called. This function prepares the
scanner for matching the LOP-expression (cf. section 6.18), and
switches to start condition x.
In start condition x, an attempt is made to match {tail}. If this
does not succeed, the catch-all rule is matched, and lop3_()
pushes two characters back on to the input stream: the character preceding the
currently first character of the tail and the just-matched character. Thus the
input now contains an incremented potential tail, and the scanner again tries
to match {tail}. This eventually succeeds, and lop2_() is called.
The member lop2_() pushes all characters initially matched for
{head}{tail}, except for the final |tail| number of characters, on to
the input stream, and switches to start condition x+1.
At start condition x+1 lop4_() is called, which pushes the characters
of the originally matched input beyond the currently matched input
characters back on the input stream. This returns the tail beyond the string
matched for {head} on to the input. Next it resets the scanner to the
start condition that was active when {head}{tail} was first
matched. Finally the original action-block's statements (if any) are executed.
Fixed length LOP-expressions do not need additional start conditions, nor do
they need catch-all rules. When the above LOP-expression uses a
fixed-length tail t, it is transformed to
{head}{tail} {
lopf_(t);
action-block
}
The member lopf_(t) simply pushed the final t characters of the
matched input back on to the input stream, resizing d_matched to
d_matched.length() - t.
Pattern constructors are used to handle LOP-expressions (see also
figure 8, showing the data-members of Pattern
objects). Pattern constructors that are used to represent LOP-patterns use
their d_lopData members. If this member is zero, the object does not
represent a LOP-pattern; if it is non-zero it points to a LopData struct,
and the object does represent a LOP-pattern.
This is the constructor used to represent a LOP expression having a fixed non-zero length LOP-tail:
Pattern(States &states, size_t tailLength,
Pattern const &lhs, Pattern const &rhs);
In this case the LopData's mid and lhs fields are not used,
and scOrLength stores the length of the fixed-length tail of the
LOP-expression.
As the pattern to match is {head}{tail}, the states of the lhs and
rhs expressions are concatenated, and the concatenated states are accessed
though the object's d_pair member.
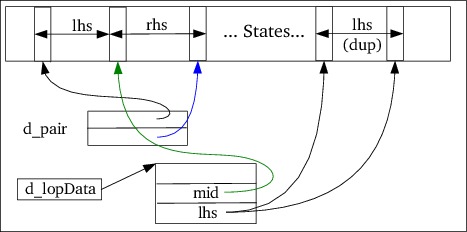
For standard LOP-expressions (having variable length tails) the next constructor is used (cf. figure 12):
Pattern(States &states,
Pattern const &lhs, Pattern const &rhs,
size_t lopStartCondition);
Here the pattern to match is, as before, the concatenated states of the
lhs and rhs patterns, which are accessed though the object's d_pair
member.
Once {head}{tail} has been matched, the tail pattern must
be matched, using a separate start condition. The state number of the
{tail} pattern's first state is stored in d_lopData->mid, and is
used later (by the Rules object) to create a specific tail-matching
rule.
The (number of the) start condition handling the tail-matching process is
lopStartCondition which is stored in d_lopData->scOrLength.
Another rule must be available to match {head}, once {tail} has been
matched. The states of this rule are accessed through d_lopData->lhs,
which is a Pattern object initialized with the states of a duplicate of
the lhs pattern. Once the {tail} has been matched, this duplicated pattern
is used to match {head} in the next start condition.
The type of a pattern is inferred from the pattern object's d_lopData
member. If zero, then the pattern does not represent a LOP-expression, and its
type (returned by its type() member) is RuleType::NORMAL. Otherwise,
if the LOP-expression has a fixed-size tail, then d_lopData->mid equals 0,
and the pattern's type is RuleType::LOP_FIXED. If d_lopData->mid is
unequal 0, then the pattern represent a standard LOP-expression, and its type
is RuleType::LOP_1.
parser/inc/regexoreof has recognized a pattern (whether or not a
LOP-expression) it is further processed by either optMs_rule (optional
start condition rule) in parser/inc/optmsrule, or by msCompound (mini
scanner compound) in parser/inc/mscompound.
In both cases the actions that are associated with the regular expressions are
determined (they may be `or-actions', in which case the action consists of a
|-character, indicating that this rule uses the same action as the next
rule, or no actions may be defined, representing an empty action block).
Having determined a pattern and action block, the combination of pattern,
action, possibly a begin-of-line requirement (i.e., a rule starting with
^), and the pattern's type are passed to d_rules.add, adding another
rule to the set of available rules.
Adding a rule (cf. rules/add.cc) means:
Rules object's d_rules
vector of rules;
d_rules, so the DFA
construction knows which rule is matched when this state is
reached. This rule-index is used as a case label in the scanner's
executeAction_ member;
setRule(pair.first, ruleIdx) to associate the rule's
states with the rule's index;
Parser::addLopStartConditions is called.
If no variable tail LOP rules were encountered, this function immediately returns. Otherwise, there are tail matching start conditions, which need a catch-all rule, and for each variable tail LOP rule two start conditions are defined.
The catch-all rule is added to the Rules object by the
Rules::processCatchAllRule member. The catch-all rule is the last rule,
injected by the scanner once it has reached the end of its input. It is stored
inside the Rules object in a separate Rule d_catchAll object.
Next the variable tail LOP rules' start conditions are defined. At this point
all user-defined rules are known, and the user-defined start conditions are
also known (as the parser has processed the %x and %s
directives). Therefore, all start conditions which are required for handling
standard LOP-rules have index values exceeding the number of user-defined
start conditions. When a standard LOP-rule was encountered by the parser,
Parser::lookahead increased its d_lopStartCondition by 2, and so at
this point d_lopStartConditions - d_rules.size() start conditions are
defined.
These start conditions are for internal use only. Their names are not made
available in the generated ScannerBase.h header file. They start with a
blank space, which can therefore not be specified in user-defined input
files. Furthermore, the code generator only adds the user-defined start
condition names to the enum class StartCondition_, defined in
ScannerBase.h, so the variable tail LOP rules' start conditions cannot be
specified by user-called begin statements.
Rules::handleLopRules performs rule-finalization.
Once the parser has completed its work, the Rules object finalizes its
rules, adding additional rules for LOP_1 type of rules.
First Rules::setLopBlocks ensures that each variable length LOP rule has
its own action block. The variable tail length LOP rules receive their own
lop1_(size_t sc) action block, but their original action blocks must
remain available, to be added eventually to the lop4_() action, after
matching the LOP rule's {head} pattern. Comparable considerations hold
true for fixed-sized tail length LOP rules. Here the rule's original action is
appended to the rule's lopf_(size_t tailLength) call.
To prepare the rules for their appropriate actions, consider figure 13.
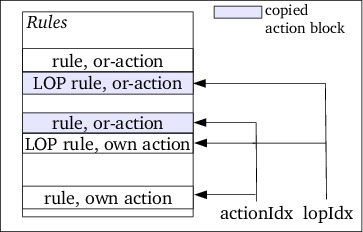
Initially, actionIdx and lopIdx point beyond the last rule index. When
a rule has an action block of its own actionIdx is given this rule's index
value: actionIdx always holds the index of the most recent rule having an
action block of its own. Likewise, lopIdx always holds the index of the
most recent LOP rule.
If a LOP rule has an or-action, then it receives a copy of the most recently seen action block. If a normal rule has an or-action then it receives a copy of the most recently seen action block if this happens to be a LOP rule's own action block.
After setLopBlock all LOP rules have their own true (i.e., not or-actions)
action blocks.
Next, all fixed tail length LOP rules are processed: each fixed tail length
LOP rule's action block receives an initial lopf_(tailSize); statement,
where tailSize is obtained from the rule's pattern.lopTailLength()
member.
If there are variable tail length LOP rules then these are processed next (by
Rules::handleLopRule(idx)).
Rules::handleLopRule receives the index of a variable tail length LOP
rule and changes its action block to lop1_(scIndex), where scIndex is
the start condition index matching this LOP rule's tail. ScIndex is
obtained from the rule's pattern->scIndex() member.
Next, the lop rule's start condition is activated at d_startConditions and
the LOP rule's {tail} pattern is added to this start condition, using
RuleType::LOP_2. This start condition also needs a catch-all rule, using
action block lop3_(), but as all variable tail length LOP rules share
this catch-all rule, they are handled separately, see below.
Finally, the lop rule's 2nd start condition is activated and
the LOP rule's {head} pattern is added to this start condition, using
RuleType::LOP_4, prefixing the original rule's action block by the
statement lop4_() (see also section 6.10.1.1).
Once all variable tail length LOP rules have been processed the catch-all rule
is added to the Rules object, using RuleType::LOP_3, and the catch-all
rule is added to each second start condition of each variable tail length LOP
rule (by Rules::addCatchAll).
am' defines the ranges ascii-0 to (but not including)
'a'; 'a'; 'b' through 'l'; 'm'; and 'n' through
ascii-255.
Likewise, sets may define ranges, like [[:digits:]], defining all
ascii characters preceding the digits; all decimal digits; and all ascii
characters following the digits.
Rather than having a NFA/DFA having entries for each of these characters the NFA/DFA's column-dimension (see section 6.13) can be reduced, often considerably, by letting each column refer to a set of characters, rather than individual characters.
The Ranges object takes care of defining and manipulating the actual
subsets. Its data organization is given in figure 14.
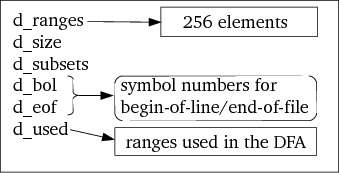
Initially d_ranges is filled with all zeroes. Once a range of characters
or a single character is defined in a pattern, it is added to the Ranges
object (functions add accepting single characters or strings). The
occurrence counts of the added characters are incremented if necessary. De
functions update, collision, and countRanges handle the updating.
Details of the algorithm are not covered here, until the need for this arises. For the time being consult the sources for details.
In the user interface the important members are rangeOf, rangeOfBOL and
rangeofEOF, returning the column indices in DFAs to which input characters
belong.
DFAs builds the various DFAs for
each of the start conditions. The DFA construction needs access to the rules,
states and character ranges, which are available to the DFAs object)
(cf. figure 15)
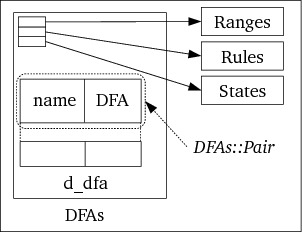
The DFAs object's real work is performed by its build member. The
build member visits all the elements of Rules, passing each of the
start conditions (stored in the Rules object) to buildDFA. For each of
the start conditions, holding the indices of the rules that are defined for
the various start conditions, a DFA is constructed for all of the rules of
that start condition (cf. figure 6.3).
The function buildDFA performs two tasks:
d_dfa vector. Each element of
d_dfa contains
Rules's
NameVector), and
DFA object (see section 6.13)
DFA function build for the just initialized
DFA, passing it the vector of indices of the start states for that mini
scanner. Build constructs the start condition's DFA, see section 6.13.
DFA object
(cf. figure 16)
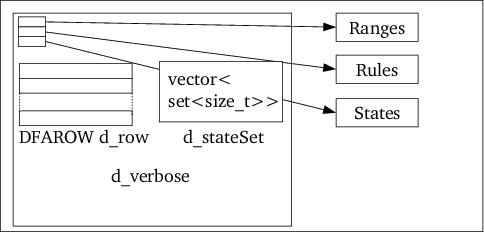
The DFA uses the externally available rules, states and character ranges
and builds a vector of DFARows, named d_row. It has the following data
members:
d_row: the vector of DFARow objects, defining the rows of the DFA
(cf. section 6.14);
d_stateSet: a vector of sets of State indices. There are as many
sets in this vector as there are elements in d_row, and each element holds
the indices of the State objects in d_states that are represented by
the matching DFARow object.
d_verbose: shadows the presence of the --verbose program flag.
DFA::build.
Each row of d_row defines a state in the DFA. The Rule numbers of the
Rules defining a start condition received as build's vector<size_t>
parameter.
DFA::build initially stores the start states of the rules of its start
condition in its d_stateSet[0]th element, which is a set (cf. figure
17). This is done by DFA::fillStartSet
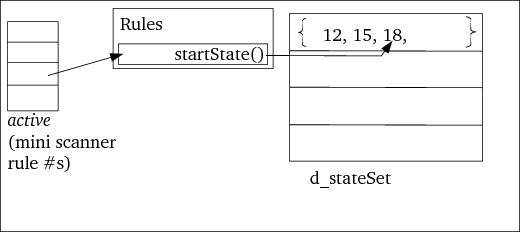
Next, the e-closure of this initial set of states is computed. The e-closure
algorithm is described in ASU's dragon book (1986, figure 3.26). It
essentially adds all states that can be reached from each element in the
current set of states on an empty transition. The e-closure is computed by
States::eClosure.
At this point there is an element in DFA::d_stateSet, but not yet an
element in DFA::d_row. By adding a DFARow (see section 6.14) to
d_row we associate a DFARow with an initial set of states.
Once the new DFA has been added to d_row its transitions are probed by
DFARow::transitions (see section 6.14).
build proceeds to remove
implied/identical rows, calling DFA::keepUniqueRows. This latter function
visits each of the rows of the DFA, testing whether an existing row has the
same transitions and final state information as the current row. `Same
transitions' means that the transitions of the current (under inspection) row
are present in an earlier row; `same final state information' means that the
current row is a final state for the same rule(s) as an earlier row. In such
situations the current row can be merged with the earlier row, keeping the
earlier row. The (later) row can then be removed as transitions from it are
identical to those from the earlier row. This may happen, as the NFA
construction algorithm may define more empty edges than strictly necessary,
sometimes resulting in additional rows in the DFAs. As an example, consider
the pattern (a|ab)+/(a|ba)+, producing the DFA
| Input Chars | |||
| StateSet | a | b | Final |
| 0 | 1 | ||
| 1 | 2 | 3 | |
| 2 | 2 | 3 | 0 |
| 3 | 4 | 5 | |
| 4 | 2 | 3 | 0 |
| 5 | 6 | ||
| 6 | 7 | 5 | 0 |
| 7 | 7 | 5 | 0 |
aba being interpreted as HEAD: a and TAIL: ba.
But when |TAIL| should be minimized aba should be interpreted as HEAD:
ab and TAIL a, resulting in transitions 0 -> 1 -> 3 -> 2, with |TAIL|
= 1. This happens when row 4 is merged to row 2. Having merged the rows,
former transitions to the now removed rows must of course be updated to the
merging row. So row 3 must transit to 2 when receiving input symbol a. The
member shrinkDFA handles the shrinkage of the DFA. In this example the
final DFA becomes:
| Input Chars | |||
| StateSet | a | b | Final |
| 0 | 1 | ||
| 1 | 2 | 3 | |
| 2 | 2 | 3 | 0 |
| 3 | 2 | 4 | |
| 4 | 5 | ||
| 5 | 5 | 4 | 0 |
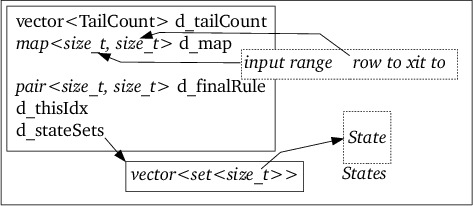
A DFARow row specification is defined by a set of states
accessible as d_stateSets[d_thisIdx]. The values of this set define the
(e-closure of the) states of this row (see section 6.13).
Each of these states may result in a transition to another state when observing a character from one of the DFA's input ranges. These `states to transit to' in turn define another set of states (possibly identical to the set of states defining the current row).
Transitions from this row are probed for each of the character ranges (in
Ranges, see 6.11) by DFARow::transitions. The member
DFARow::transitions may add new elements to d_stateSet, continuing the
iteration until eventually there are as many d_row elements as there are
d_transitions elements.
If this set of states to transit to is not yet present in the DFA then a
new row is added to the DFA. Adding rows is the task of DFA::build,
defining and adding new sets of States is the responsibility of
DFARow::transition.
d_map: the DFARow's unordered_map d_map defines the
relationship between an input character range (the map's key) and the row to
transit to when a character from that input range has been observed.
d_finalRule: the elements of the pair d_finalRule are indices of
rules in Rules for which this DFARow represents a final state. The
first element of the pair refers to a rule whose RE not necessarily starts
at BOL, the second element refers to a rule whose RE must start at
BOL. When a value equals UINT_MAX then the current row is not a final
state for such a rule.
d_thisIdx: the index of the current DFARow element in its DFA
matrix.
d_stateSets: this data member is a pointer to a vector containing
sets of states represented by the rows of the DFA. Element
d_stateSets[d_thisIdx] is the set of states represented by the current DFA
row.
d_final are set by setFinal, called from
DFARow::transit. It receives the the rule index
given the index of the row's State.
If the rule index refers to a BOL rule d_finalRule.second is inspected,
otherwise d_finalRule.first is inspected.
If the inspected value doesn't refer to a rule yet, the current rule index is assigned. Otherwise, if the current rule type (NORMAL or LOP-rule) equals the rule index's type, and the rule index is smaller than the inspected element's value, or if the rule index refers to a NORMAL rule, but the inspected element doesn't, then the rule index is assigned to the inspected element.
Thus a DFA row will always be associated with the first rule that reaches its final state at the current DFA row if both rules are of identical types, and it will be associated with the NORMAL rule if the other rule is not a NORMAL rule.
DFA::build transitions are determined for each new row;
DFARow::transitions;
DFARow::transitions DFARow::transit transitions on the
current input character are determined
DFARow::transit, if the current state is a FINAL state,
the rule that is matched is determined by DFARow::setFinal
Each DFARow has a std::pair<size_t, size_t> d_finalRule data
member. In setFinal a rule index is received. If the matching rule is a
BOL-rule then d_finalRule.second is determined, otherwise
d_finalRule.first.
When multiple rules could match at a final state, then the rule mentioned
first takes precedence. Since the elements of d_finalRule are initialized
at max<size_t>(), the received rule index is assigned to the appropriate
d_finalRule field if it's smaller than the currently stored value.
Once the DFAs have been constructed, the viability of the rules is determined
by DFAs::warnNonViable. This function is called from main.
DFAs::warnNonViable first defines the set of all user-defined rule
indices. Next it visits all DFAs not having numeric names (as these are
internally defined DFAs added by the DFA construction process for LOP-rules),
removing all rules that can be matched at their DFA rows from the set of rule
indices. If any indices remain in this set then these rules cannot be matched,
and a warning is issued for each of them.
Be cautious when defining LOP patterns allowing empty head-matches. The
following series of rules result in rule 2 never being matched: an ab
sequence matches the tail of rule 1, with an empty head. Next, ab is
re-scanned and the procedure repeats itself:
[[:blank:]]+
a*/a*b d_p = "a*/a*b"; return 1;
ab d_p = "ab"; return 2;
. d_p = "."; return 3;
The repair consists of reordering these rules, or disallowing an empty
LOP-head. Reordering the rules solves the problem:
[[:blank:]]+
ab d_p = "ab"; return 1;
. d_p = "."; return 2;
a*/a*b d_p = "a*/a*b"; return 3;
Now rule 1 takes priority over rule 3: an ab sequence is matched by
rule 1, rather than becoming rule 3's tail.
Likewise, with the following set of rules rule 2 will never match, as the LOP
rule recognizes the \n (realize that $ means: /\n):
//%nowarn
.*$ d_p = ".*$"; return 1;
\n
Again, reordering (or using a non-empty LOP head) solves the
problem. E.g., using reordering:
\n
//%nowarn
.*$ d_p = ".*$"; return 1;
Generator. The generator
generates the following files (using default names, all defaults can be
overruled by directives and options):
Scannerbase.h. This file defines the scanner's base class. It is always
rewritten and declares data members used by the scanner.
Scanner.h. This file represents the generated scanner's interface. It
inherits from ScannerBase and is written only if not existing.
Scanner.ih. This file represents the generated scanner's internal
header file. The internal header file is part of a design philosophy
according to which all source files belonging to a class should merely include
the internal header file, which declares all headers and other elements that
are required for the correct compilation of the class's source files.
lex.cc This file contains the implementation of the scanner function and
any support functions it may need. This file is always rewritten.
Each of these files has a skeleton, found in /usr/share/flexc++ (the
development header files are in the skeletons/ subdirectory of the source
package). The skeletons are the templates (molds) from which the files
matching the requirements as defined in flexc++'s input s are created:
lex.cc file;
lex.cc;
Scannerbase.h
file.
genLex generates the lexer file lex.cc. It recognizes
$insert lines starting in column 1 and performs the matching action,
inserting appropriate elements into the generated file.
Other generating members act similarly:
The member genBase generates the scanner base file Scannerbase.h, the
member genScanner generates Scanner.h.
The code generated by flexc++ must read input, match the input with some
regular expressin and return the associated token. A catch-all escape is
provided by the implicitly provided rule echoing all non-matched input to the
standard output stream.
The generated code consists of these parts:
Generator::dfas.
For each of the DFAs the function Generator::dfa is called.
The function Generator::dfa receives as its first argument a
DFAs::Pair (see figure 15), containing the name of the
start condition that is associated with the DFA and the DFA itself.
The function performs the following tasks:
startStates (to allow checking for repetitive handling);
s_dfa
is saved in the vector dfaOffsets;
Generator::dfaRow is called for each row of the DFA (see figure
18). This latter function writes the vector of DFA rows to
transit to (i.e., rows relative to the current DFA's start row, so not
the actual rows in s_dfa) for each of the character ranges
(calling Generator::dfaTransitions), followed by the number of the
rule that is matched if the rule represents a final state not
necessarily at BOL and the number of the rule that is matched if the
rule represents a final state at BOL. Values -1 are used if no such
rules exist for the state represented by the current row.
The function Generator::declarations adds the declarations of
(*d_dfaBase_)[], s_dfa_[][], s_dfaBase_[][] etc. to ScannerBase.h,
providing these declarations with their required (higher order) dimension
values.
The function Generator::actions inserts the actions in the function
ScannerBase::executeAction_, implemented in lex.cc. Actions are
inserted separately for each RuleType that was used. Each NORMAL,
LOP_1, LOP_4 and LOP_FIXED (fixed-tail LOP rule) type of rule has its own
action block, and their action blocks are inserted first. LOP_2 and
LOP_3 actions are all identical, and flexc++ creates a set of fall-through
case labels for these actions.
The function Generator::charTable defines in d_out the static
data member size_t const ScannerBase::s_ranges[]. This array has 256
elements, so each character (cast to type unsigned char) can be used as
an index into this array, returning its range-number.
In addition to real input characters, the scanner may return two pseudo
range values: rangeOfBOL is the range matching the special `character'
BOL, returned when a begin-of-line is sensed, and rangeOfEOF which is
returned when EOF was sensed (e.g., when the <<EOF>> rule was used).
These BOL and EOF tokens must be returned by nextChar when BOL or EOF was
sensed, and the DFA's recognizes their ranges. The ranges rangeEOF and
rangeBOL are declared in the scanner class's data members section.
If DFA's don't recognize BOL or EOF characters then the default action is performed: BOL is ignored and EOF results in switching back to the previous stream or in returning token 0 (and ending the scanning-process).
The code generator adds code handing BOL and EOF to scanners using these pseudo characters. The code is left out of the generated scanner if these pseudo characters are not used.
Range tables are generated by generator/chartable.cc.
Generator::dfas, defined in generator/dfas defines
defines in d_out the static data member int const
ScannerBase::s_dfa[][dfaCols()], where dfaCols returns the number of
columns of the DFA matrices.
All DFAs are accessed through this single s_dfa matrix. Each
individual DFA starts at a specific row of s_dfa. The first DFA to be
written is associated with the INITIAL scanner: INITIAL is always
defined and contains all rules not explicitly associated with a start condition.
The matrix s_dfa contains the rows of all DFAs, including those that
were generated by flexc++ itself, with the start state INITIAL always
being the first DFA.
Each row contains the row to transit to if the column's character range was
sensed. Row numbers are relative to the used DFA. There are as many elements
in the rows of the s_dfa table as there are character ranges plus
two. These final elements represent rule indices of, respectively, the matched
rule (normal case) and the matched rule in case of BOL. The value -1 is used
if no such rule is associated with the DFA row.
The base locations for the various start conditions are defined in the
static array s_dfaBase. Its initial value matches the INITIAL scanner,
and points to the first s_dfa row. Additional values are defined for each
additional start condition, and point to the initial rows in s_dfa for
these start conditions. Here is an example of a enum class Begin and
matching s_dfaBase:
enum class Begin
{
INITIAL,
str,
};
std::vector<int const (*)[9]> const ScannerBase::s_dfaBase =
{
{ s_dfa + 0 },
{ s_dfa + 6 },
};
The INITIAL scanner's dfa rows start at the top, the str mini
scanner starts at row index 6 of s_dfa.
lex function works as follows:
d_atBOL is set to
true.
Characters from the input are assigned to d_char. At the beginning of the
character processing loop d_char already has received a value. At EOF the
character is given the (pseudo) character value AT_EOF.
Next, the character's range (d_range) is determined from
s_ranges[d_char].
The variable d_dfaBase points at the dfa currently used. The variable
d_dfaIdx holds the index of the current row in the current dfa.
The expression
nextIdx = (d_dfa + d_dfaIdx)[d_range];
provides the next d_dfaIdx value. If unequal -1 do:
d_dfaIdx = nextIdx;
d_char = nextChar();
If equal -1 then there is no continuation for the current rule.
Depending on the current state and action several action types can be returned
by the run-time function actionType_:
CONTINUE: there exists a continuation from the current state/range
combination;
MATCH: a final state has been reached and there's no continuation
possible. In this case a rule has been matched
ECHO1ST: no continuation is possible for the current range, and no
final state was reached, the input buffer contains one or more
characters.
ECHOCHAR: no continuation is possible for the current range, no
final state was reached and the input buffer is still empty
RETURN: input exhausted, lex returns 0.
The following table shows how actions are determined by actionType_. The
function actionType_ starts it tests at the first row of the table, and
stops as soon as a condition hold true, returning the action type:
Action determined by actionType_ |
||
| Input Character | ||
| Performed Test | not AT_EOF | AT_EOF |
| transition OK | CONTINUE | CONTINUE |
| match found | MATCH | MATCH |
| buffer size | ECHO1ST | ECHO1ST |
| buffer empty | ECHOCHAR | RETURN |
For each of the returned action types actions must be performed:
CONTINUE: store the input character (not being AT_EOF) in the
buffer, continue scanning
MATCH: push the just read char back to the input, copy the non-pseudo
character (i.e., other than AT_EOF) to the match-buffer, set
d_atBOL to true if the last character in the d_matched
buffer is '\n', execute postCode(PostEnum_::RETURN), execute
the rule's actions, continue scanning (but the action may end
lex's call).
ECHO1ST: echo the 1st char. of the buffer to stderr, set d_atBOL
to true if that character equals '\n', otherwise to false,
return all but the first character in the buffer back to the input,
call postCode(PostEnum_::WIP), continue scanning.
ECHOCHAR: echo the just read character to stderr, set d_atBOL
to true if that character equals '\n', otherwise to false,
continue scanning.
RETURN: if popStream returns false, then execute
postCode(PostEnum_::END) and member lex_ returns with token
value 0; otherwise postCode(PostEnum_::POP) is called and
processing continues.
The data member d_atBOL is also set to true when lex_ switches to
another input stream (either a new one, or returning to a previously stacked
one). This handles the borderline case where a file's last line is not
properly terminated with a '\n' character.
ScannerBase::knownFinalState (implemented in ScannerBase.h
returns
(d_atBOL && available(d_final.atBOL.rule))
||
available(d_final.notAtBOL.rule);
only if this is true, ScannerBase::actionType_ returns
ActionType_::MATCH.
Three variables are used here, resulting in 8 possibilities:
| available rule | |||||
| nr | d_atBOL | std | bol | action | |
| 1 | 0 | 0 | 0 | prevented by knownFinalState | |
| 2 | 0 | 0 | 1 | prevented by knownFinalState | |
| 3 | 0 | 1 | 0 | use the std. rule | |
| 4 | 0 | 1 | 1 | use the std. rule | |
| 5 | 1 | 0 | 0 | prevented by knownFinalState | |
| 6 | 1 | 0 | 1 | use the BOL rule | |
| 7 | 1 | 1 | 0 | use the std rule | |
| 8 | 1 | 1 | 1 | different match lengths: use | |
| the rule matching the longest text; | |||||
| equal match lengths: use the earlier rule. | |||||
skeleton/flexc++.cc's
member matched_.
ScannerBase.h adds the following data members to ScannerBase.h:
int d_lopSC = 0; // the active SC when lop1_()
// is called
std::string d_lopMatched; // matched lop-rule characters
std::string::iterator d_lopTail; // iterator pointing to the first
// character of the tail the scanner
// is trying to match against {tail}.
std::string::iterator d_lopEnd; // iterator indicating the end of the
// text to match agains {tail} or the
// end of the text to match against
// {head}
std::string::iterator d_lopIter; // iterator iterating from d_lopTail
// to d_lopEnd while trying to match
// {tail}
size_t d_lopPending; // # pending input chars when lop1_
// is called
// pointer to the input function.
size_t (\@Base::*d_get)() = &\@Base::getInput;
After matching tt{{head}{tail}) of fixed length tail LOP rules, the matched
text is first processed by lopf_(tailLength), before the LOP rule's
original action block is executed. If fixed length tail LOP rules are used,
then lopf_(tailLength) is implemented in lex.cc and looks like this:
void ScannerBase::lopf_(size_t tail)
{
tail = length() - tail;
push(d_matched.substr(tail, string::npos));
d_matched.resize(tail);
}
This member simply pushes the last tail number of characters back to
the input stream, and removes them from d_matched.
After matching tt{{head}{tail}) of variable length tail LOP rules,
lop1_(size_t lopSc) is called. This member prepares the scanner for
finding the shortest tail. It's implementation is:
void ScannerBase::lop1_(int lopSC)
{
d_lopMatched = d_matched; // local copy of the matched
// text
d_lopPending = d_input.nPending(); // remember the # of pending
// characters in Input's queue
d_lopEnd = d_lopMatched.end(); // initialize the iterators
d_lopTail = d_lopEnd - 1; // to the final substring
d_lopIter = d_lopTail; // of one character
d_get = &ScannerBase::getLOP; // obtain characters from
// d_lopIter
d_lopSC = d_startCondition; // remember original SC
begin(SC(lopSC)); // activate the
// tail-matching SC
}
Note the used of the member Input::nPending. This member is added to
the class Input's interface and should return the number of characters
currently in the Input object's pending queue. In the default
implementation it simply returns the Input object's d_deque's length.
To match the shortest tail lop2_ and lop3_ are used. The member
lop3_ is called when the current tail characters do not match
{tail}. It increments the tail, and resets d_lopIter:
void ScannerBase::lop3_()
{
d_lopIter = --d_lopTail; // increase the tail
}
The member lop2_ is called when {tail} has been matched. It defines
the initial characters, up to d_lopTail as the characters to match agains
{head} and starts the next next start condition, which handles the matched
{head}. Here is lop2_'s implementation:
void ScannerBase::lop2_()
{
d_lopEnd = d_lopTail; // read the head
d_lopIter = d_lopMatched.begin();
begin(SC(d_startCondition + 1)); // switch to the head-matching
// SC
}
Finally, lop4_ returns the scanner to its original state, having matched
{head}, and pushes the remaining characters (the actual tail) on to the
input stream:
void ScannerBase::lop4_()
{
begin(SC(d_lopSC)); // restore original SC
d_get = &ScannerBase::getInput; // restore get function
d_input.setPending(d_lopPending); // reduce # pending chars to
// the original number
// reinsert the tail into the
// input stream
push(d_lopMatched.substr(length(), string::npos));
}
As stated in the code, the member Input::setPending resets the number
of pending characters to its original value. Its default implementation is
void setPending(size_t size)
{
d_deque.erase(d_deque.begin(), d_deque.end() - size);
}
lex().
In flexc++'s distribution the shell script reflex is found. In an
interactive process it performs the required steps by which flexc++ recreates
its own scanner. The script assumes that a new binary program, representing
the latest changes, is available as ./tmp/bin/flexc++, relative to the
directory in which the reflex script is found. When creating flexc++
with the provided build script, these assumptions are automatically met.
The reflex script then performs the following steps:
./self.
scanner/lexer to ./self, allowing flexc++ to create a
separate lex.cc and Scannerbase.h.
./self it executes
../tmp/bin/flexc++ -S ../skeletons lexer
by which the new flexc++ program creates a scanner from its own scanner
specification file.lex() function that was created by an older scanner generator.
lex.cc and
scannerbase.h files were properly backed up.lex.cc and Scannerbase.h, created in the previous step
are now copied to the ./scanner directory.
Scanner and Parser classes as well
as flexc++.cc itself must now be recompiled, unless absolutely no changes
were made to the Scanner's internal data organization were made, in which
case build program will only recompile the modified source file
./scanner/lex.cc.lex.cc
implementation generated by the latest release of flexc++.
./self
../tmp/bin/flexc++ -S ../skeletons lexer
by which flexc++ creates a scanner from its own scanner
specification file, now using its own generated implementation of the
lex() function in lex.cc.
diff ./scanner/lex.cc self/ only shows different time
stamps and if diff ./scanner/Scannerbase.h self/ also
only shows different time stamps, then flexc++ could recreate its own matching
function and a stable new release has been created.